I maintain strong conviction that if a good programmer uses llm in their work, they just add more work for themselves, and if less than good one does it, they add new exciting and difficult to find bugs, while maintaining false confidence in their code and themselves.
I have seen so much code that looks good on first, second, and third glance, but actually is full of shit, and I was able to find that shit by doing external validation like talking to the dev or brainstorming the ways to test it, the things you categorically cannot do with unreliable random words generator.
That’s why you use unit test and integration test.
I can write bad code myself or copy bad code from who-knows where. It’s not something introduced by LLM.
Remember famous Linus letter? “You code this function without understanding it and thus you code is shit”.
As I said, just a tool like many other before it.
I use it as a regular practice while coding. And to be true, reading my code after that I could not distinguish what parts where LLM and what parts I wrote fully by myself, and, to be honest, I don’t think anyone would be able to tell the difference.
It would probably a nice idea to do some kind of turing test, a put a blind test to distinguish the AI written part of some code, and see how precisely people can tell it apart.
I may come back with a particular piece of code that I specifically remember to be an output from deepseek, and probably withing the whole context it would be indistinguishable.
Also, not all LLM usage is for copying from it. Many times you copy to it and ask the thing yo explain it to you, or ask general questions. For instance, to seek for specific functions in C# extensive libraries.
That’s why you use unit test and integration test.
Good start, but not even close to being enough. What if code introduces UB? Unless you specifically look for that, and nobody does, neither unit nor on-target tests will find it. What if it’s drastically ineffective? What if there are weird and unusual corner cases?
Now you spend more time looking for all of that and designing tests that you didn’t need to do if you had proper practices from the beginning.
It would probably a nice idea to do some kind of turing test, a put a blind test to distinguish the AI written part of some code, and see how precisely people can tell it apart.
But that’s worse! You do realise how that’s worse, right? You lose all the external ways to validate the code, now you have to treat all the code as malicious.
For instance, to seek for specific functions in C# extensive libraries.
And spend twice as much time trying to understand why can’t you find a function that your LLM just invented with absolute certainty of a fancy autocomplete. And if that’s an easy task for you, well, then why do you need this middle layer of randomness. I can’t think of a reason why not to search in the documentation instead of introducing this weird game of “will it lie to me”

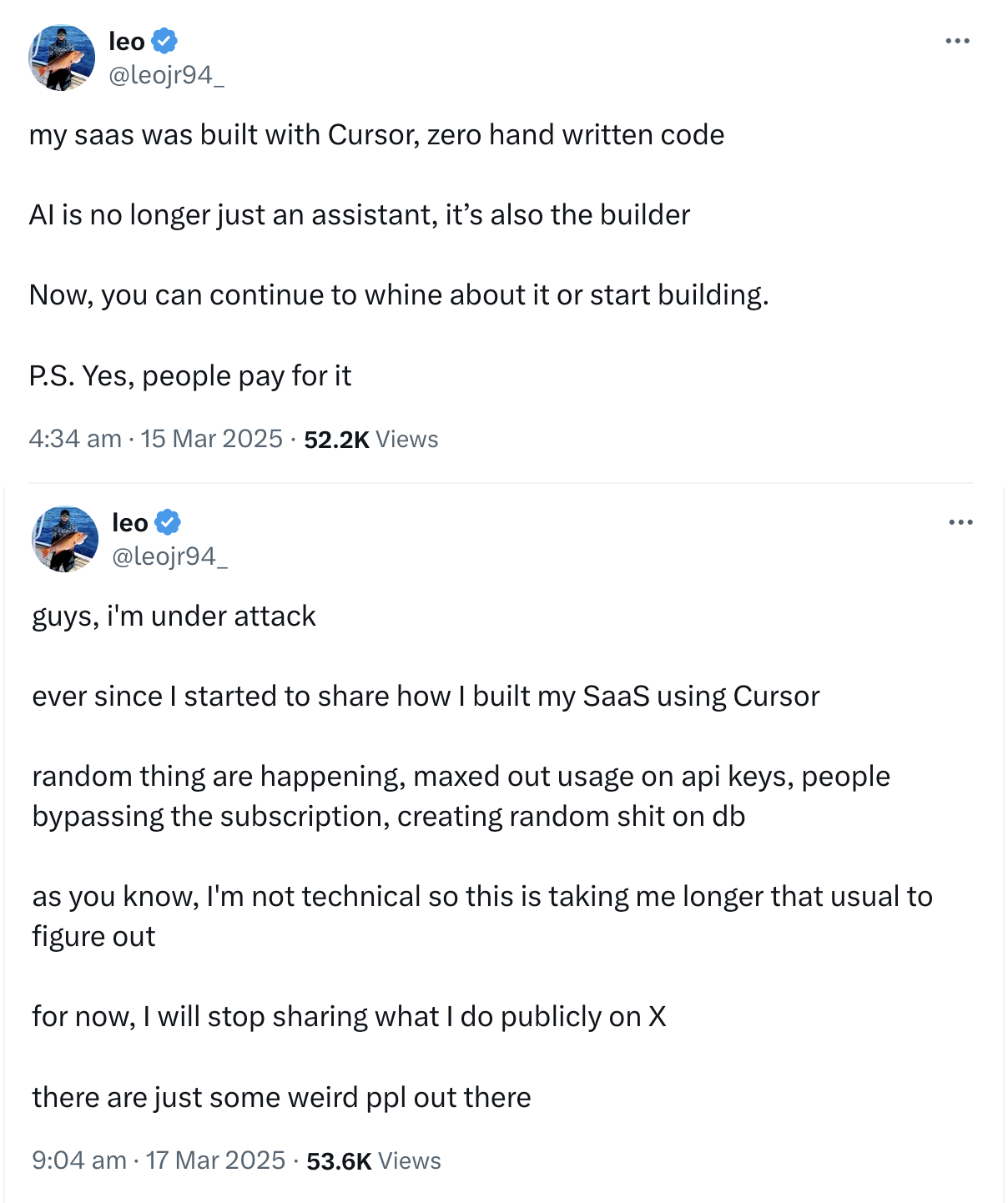{kind=link}
I maintain strong conviction that if a good programmer uses llm in their work, they just add more work for themselves, and if less than good one does it, they add new exciting and difficult to find bugs, while maintaining false confidence in their code and themselves.
I have seen so much code that looks good on first, second, and third glance, but actually is full of shit, and I was able to find that shit by doing external validation like talking to the dev or brainstorming the ways to test it, the things you categorically cannot do with unreliable random words generator.
That’s why you use unit test and integration test.
I can write bad code myself or copy bad code from who-knows where. It’s not something introduced by LLM.
Remember famous Linus letter? “You code this function without understanding it and thus you code is shit”.
As I said, just a tool like many other before it.
I use it as a regular practice while coding. And to be true, reading my code after that I could not distinguish what parts where LLM and what parts I wrote fully by myself, and, to be honest, I don’t think anyone would be able to tell the difference.
It would probably a nice idea to do some kind of turing test, a put a blind test to distinguish the AI written part of some code, and see how precisely people can tell it apart.
I may come back with a particular piece of code that I specifically remember to be an output from deepseek, and probably withing the whole context it would be indistinguishable.
Also, not all LLM usage is for copying from it. Many times you copy to it and ask the thing yo explain it to you, or ask general questions. For instance, to seek for specific functions in C# extensive libraries.
Good start, but not even close to being enough. What if code introduces UB? Unless you specifically look for that, and nobody does, neither unit nor on-target tests will find it. What if it’s drastically ineffective? What if there are weird and unusual corner cases?
Now you spend more time looking for all of that and designing tests that you didn’t need to do if you had proper practices from the beginning.
But that’s worse! You do realise how that’s worse, right? You lose all the external ways to validate the code, now you have to treat all the code as malicious.
And spend twice as much time trying to understand why can’t you find a function that your LLM just invented with absolute certainty of a fancy autocomplete. And if that’s an easy task for you, well, then why do you need this middle layer of randomness. I can’t think of a reason why not to search in the documentation instead of introducing this weird game of “will it lie to me”