Try
docker run liquidtrees:micro-algae
Try
docker run liquidtrees:micro-algae
All four cores at 100%? We don’t see that kind of spike when we open some other application right? Is it the experience of everyone? Or am I wrong in this?

Isn’t ‘innerHTML’ considered unsafe? Can someone with subject knowledge please explain.

What is the issue with Intel CPUs? I’m OOTL here.
I think I got the idea. So essentially a new copy of the file is created and stored only if there is a change, else it just refer to the older SHA. Am I right? Now I understand why LFS was needed for binaries, else it createds a lot of storage problems, but not the huge monorepos.
I’m not a developer, but a design person who covers much more including architecture. But in my org I happen to teach developers how to use Git. Strange, I know. But that is the case. It gave me a good opportunity to learn Git in depth.
I went through your blogs and patch stack workflow. I have to say that I have not been happy with the branching workflow and I always felt that is not the best (I agree to the point about “unjust popularity”). The patch stack workflow makes more sense to me. Unfortunately we won’t be able to adopt, since getting everyone to Git itself was a huge effort. Also developers are not that keen into creating good code, but just working working code. I’m extremely frustrated with that.
Also your blog design is really good. I love it. I always wanted to create something like that. But never managed to sit down and do it. Can you give me a brief about the tech stack used for the blog?
Do you use RNote for diagrams? The style looks familiar. Or is it something else?
Aah. I assumed linting was part of the build also. My bad. I did understand the idea you were mentioning. Just that assumptions kind of threw me off.
I wanted to ask something related to that. As you mentioned, git takes a snapshot of the repo on every commit. So splitting up the bug fix and other activities means you have 3 or 4 commits instead of one. Let us say we are dealing with a very large repo. This does not look ideal in that context right? So do you think the way you proposed is only suitable for smaller repos?
So this bit confuses me. The article says in the intent and scope section that the entire process of bug fixing, in the included example, is literal bug fixing, clean up toggle, correct lints, correct duplication. That point to linting issues.
The earlier section says that a commit should be ‘buildable’ and ‘testable’. So if there are linting issues, the commit won’t satisfy this criteria right?
What am I missing here?
I have a different experience. There was one thread which linked to a github issue. The issue said some blobs don’t have source code. Ironically when I went on to check, the blobs mentioned in the issue had source code, but there were other blobs which seemed to miss the source or build instructions.
I would love to have an independent audit to put this issue at rest. All that happens is more and more noise and no resolution. I am not a programmer so can’t really help here.

The first messenger without user IDs, Other apps have user IDs: Signal, Matrix, Session, Briar, Jami, Cwtch, etc. SimpleX does not, not even random numbers. This radically improves your privacy.
The project already started to diverge. If you have an older version don’t update until you migrate.
(Sorry in advance…)
Look, a meme Heimdall.
It works but I don’t think Forgejo plans to support it in the future. Gitea and Forgejo started to diverge and the documentation regarding docker is somewhat in a deprecated state.
Edit: I also think the OP’s question is different from this. So this might not be a solution.

Aah… I completely forgot about that. Will try next time. Also yesterday I saw Shift + F10 will show the context menu. Yet to test it on this site.
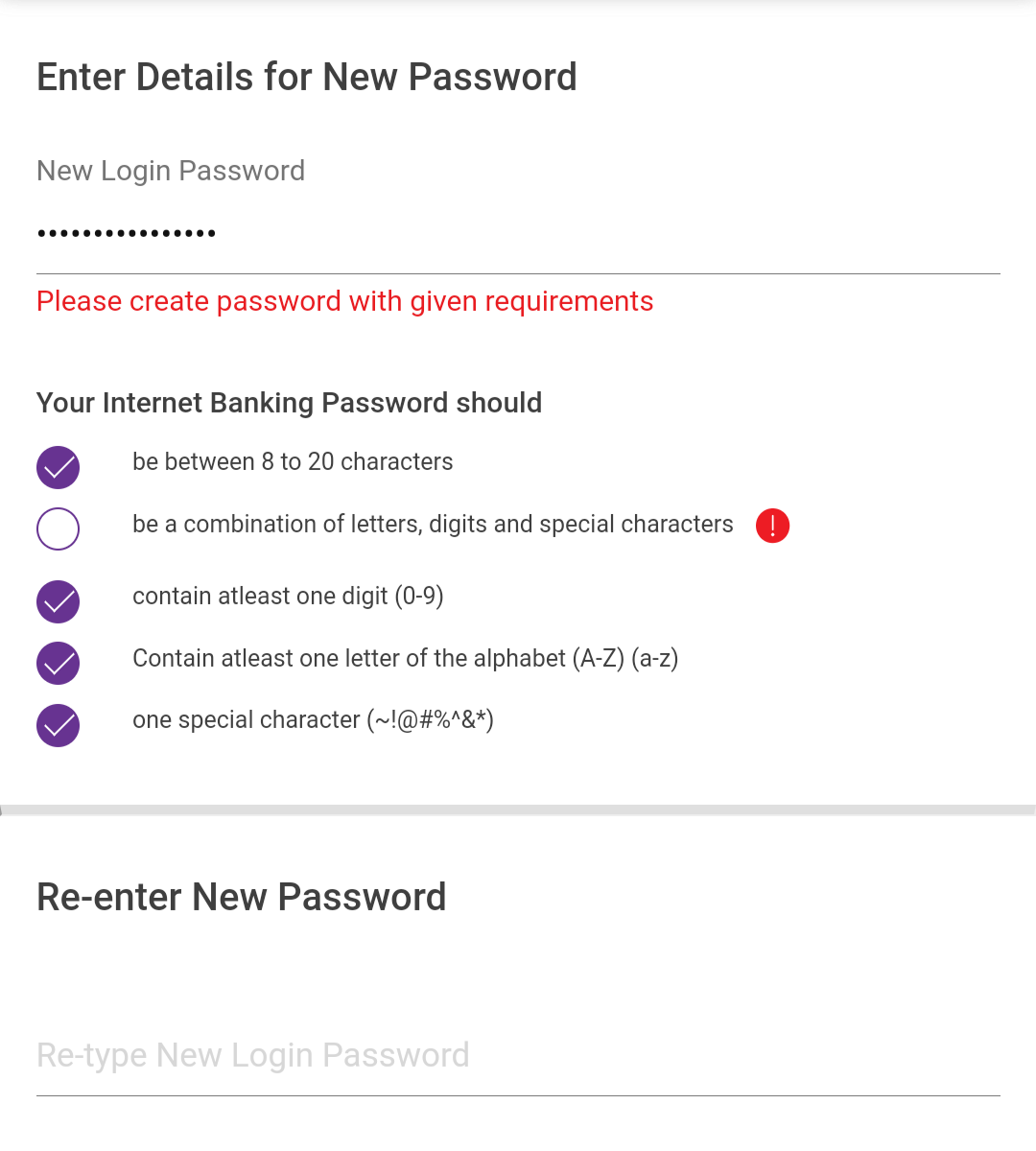
Yeah that’s true. The UI does not accurately represent the validation conditions.
Their desktop site is even more shitty. It won’t allow right click or paste actions. There goes compatibility with password managers.
Holy shit!! You did it. I would never expect a banking password to max special characters. I have been scratching my head with Bitwarden and this shitty app for an hour.
Great to see you in the wild again! Any update from Immich devs?
Open media vault and monero? But why?
Also Ollama in a 10 year old laptop will be fun.

Hey I understood what you meant. The result that you are trying to achieve is very close to the browser caching normally present is what I meant. When you zoom in it will only load that area. And I don’t think you can specify the number of tiles to be a specific number, since the zoom levels are not linear.
The offline leaflet I shared in the previous comment actually does the same thing you want to achieve. The difference is the offline mode is discarded immediately when the system is back online. So that library could be modified to incorporate the time dependency and users visiting a point again I specified in the last comment, at least in theory.
Regarding OSM data, there are zip files available for downloading. Geofabrik and openstreetmap.fr are examples. Another tool is Protomaps, where you can download by drawing a polygon. But these are not going to be the ideal solution for a product like Immich.
By the way I saw your update. Great job on following up and providing a fix for others. I really really appreciate it.

{kind=link}
Spoiler
What is the rationale for all comparisons returning false for IEEE754 NaN values?