- 3 Posts
- 21 Comments
Joined 2 years ago
Cake day: June 14th, 2023
You are not logged in. If you use a Fediverse account that is able to follow users, you can follow this user.

 0·9 months ago
0·9 months agoWow, thanks, I have not seen this comment, yet I hinted about this in some of my other replies that I’ve done before.
Yes, I think ML is fair use, but there it would also be fair to force something into the public domain/open source if, in order to be accrued, it has to make use of fair use at unseen amounts of scale.
This would be a difficult to make law, though. Current ML is very inefficient in the amount of data it requires, but it could (and should) be made better.
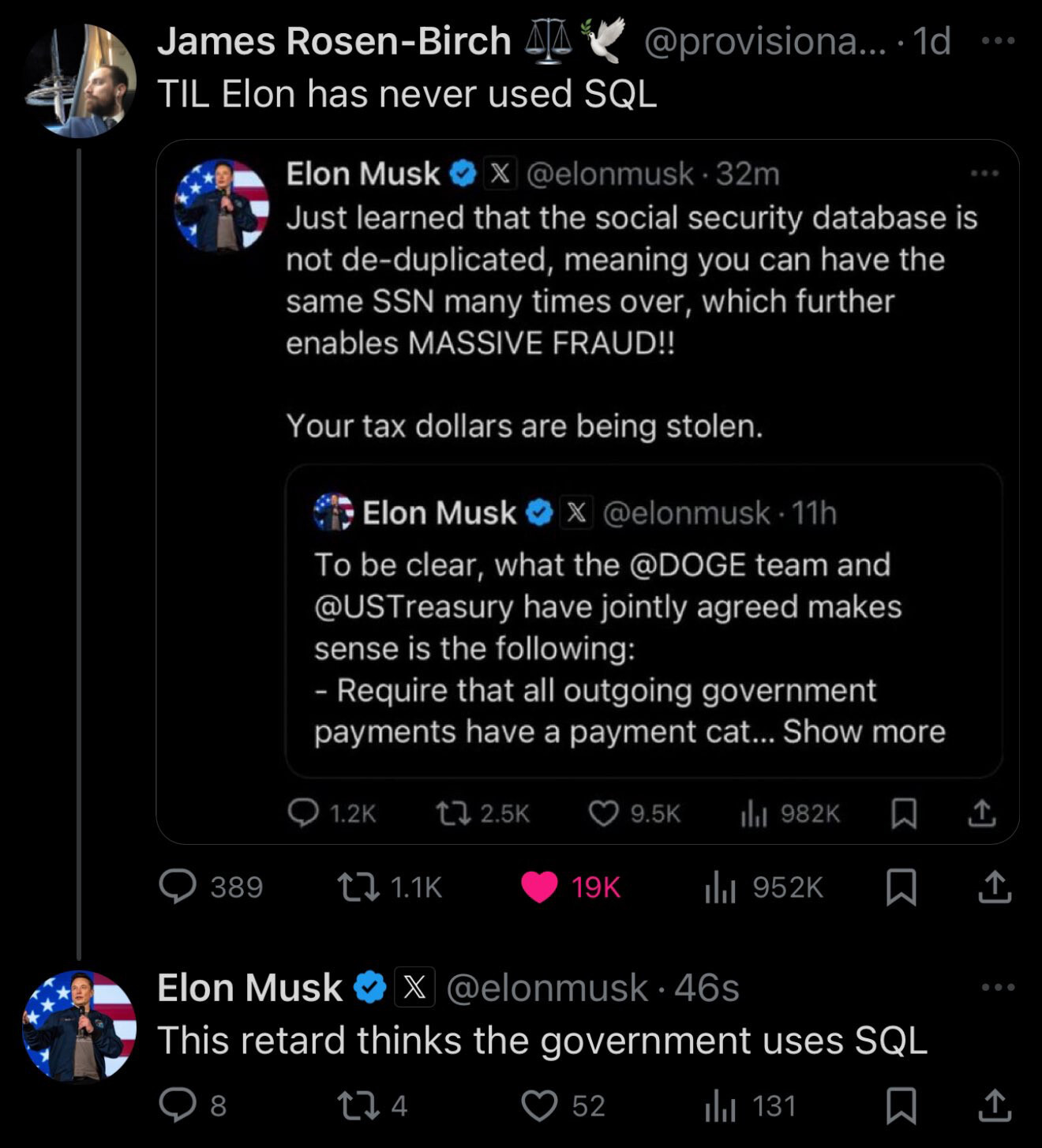
It’s not AI
It’s not AGI, it’s not general intelligence, and it’s not comparable to a human (well, you can compare anything, but human and ML are just very different things in tons of ways).
But it is AI. The ghosts that chase Pacman are AI. A search algorithm is also AI, dammit. Of course an LLM is AI. Any agent that maximizes a function is AI. You are just embarrassing yourself.
But then it does go on to quote materials verbatim, which shows it’s not “just” ‘extracting patterns’.
Is is just extracting patterns. Is making statistical samples of which token (“word”, informally speaking) is likely followed given the previous stream.
It can only reproduce passages of things it has seen many, many times. I cannot reproduce the whole work. Those two quotes can be seen elsewhere on the internet plenty of times. And it’s fair use there, so it would be fair use with a chat bot as well.
There have been papers published where researchers were able to regenerate an image that was present in the training set of Stable Diffusion. But they were only able to find that image (and others) in particular, because they were present in the training set multiple times, and the caption was the same (it was the portrait picture of some executive at a company).
when given the book and pages — quote copyrighted works
Yeah, you are not gonna be able to do that with an LLM. They will be able to quote only some passages, and only of popular books that have been quoted often enough.
Even if they started to use my service to literally copy entire books?
You cannot do that with an LLM.
Why are you defending massive corporations who could just pay up? Isn’t the whole “corporations putting profits over anything” thing a bit… seen already?
I hate that some corporations are burning money, resources and energy on this, and the solution is not to restrict fair use even further. Machine Learning is complex, but if I had to summarize in some way is “just” gathering statistics of which word comes next (in the case of a text model). This is no different than getting a large corpus of text, and sample it for word frequency, letter frequency, N-gram frequency, etc. It is well known that this is fair use. You only store the copyrighted works to run the software and produce a very transformative work that is a summary many orders of magnitude smaller than the copyrighted work. This is fair use, and it should still be. Changing that is gonna harm the public, small companies and independent researchers way more than big tech companies.
As I said in another comment, I would very much welcome a way to force big corpos to release their models. Make a model bigger than N parameters? You needed too much fair use in one gulp: your model has to be public, and in the public domain. I would fucking welcome that! But going in the opposite direction is just risky.
I don’t understand why small individuals think that copyright is their friend, and will protect them from big tech companies. Copyright will always harm the weak and protect the powerful as a net result. It’s already a miracle that we can enjoy free software and culture by licenses that leverage copyright in our favor.
“Theft” is never a technically accurate word when dealing with the so called “intellectual property”, because the digital content being copied without authorization is legal in tons of cases, and because, come on, property is very explicitly exclusive. I cannot copy my house or my car, but I can make copies of my works for virtually 0 cost.
Using data for training ML models is even explicitly allowed in some jurisdictions (e.g. Japan), and is likely to be fair use everywhere else. LLMs are very transformative, and while they often can produce verbatim copies of fragments of copyrighted works, they don’t store the whole works or significant pieces of them.
Don’t get me wrong, I don’t like big companies making big money. I would not mind a law that would force models to be open sourced. But restricting them to train their models on public data by restricting fair use, it would harm them very little (they could pay something if they are making some profit), while small researchers or companies would never be able to compete, because they would not have the upfront costs, nor the economic engineering to disguise profits and pay less.
 19·1 year ago
19·1 year agoYes. There is already an answer with many votes saying so, but I’ll add myself to the list.
I don’t have to like all the language, and not even all of the standard library. I learnt C++ with the Qt library, and I still do 99% of my development using Qt because it’s the kind of software that I like to write the most. I can choose the parts that I like the most about the full C++ ecosystem, like most people do (you would have to see how different game development is, for example).
I’m also learning Rust, and I see nothing wrong with it. It’s just that I see C++ better for the kind of stuff that I need to write (at this time at least).
Correct. Backwards compatibility is both its biggest asset and its bigger problem.
In syntax alone, you can check what Herb Sutter is doing with cppfront. Specifically, the wiki page on the postfix operators is quite enlightening. It shows some interesting examples of how by making everything a postfix operator you drop the need of
->and the duality of pre/post increment and decrement operators.
Klipper was entirely a different program, process, etc. that was using the system tray. Nowadays it seems to be a plasmoid in the system tray. How can that be less of a UNIX philosophy than the Windows alternative? Because it’s developed by the same community that makes the shell? That doesn’t make sense to me.
They are. Registers are just “named boxes” where you can store some text and/or keystrokes. When yanking and pasting, the unnamed register is used if you don’t specify a name (you can still see or edit it explicitly). For recording a macro there is no default register, though. You need to give it a name.
Meanwhile, this was a feature on KDE-land since Klipper, which goes back (as far as I know and if I remember well) to KDE 3 or sooner.
I’d have to dig it, but I think it said that it added the PID and the uninitialized memory to add a bit more data to the entropy pool in a cheap way. I honestly don’t get how that additional data can be helpful. To me it’s the very opposite. The PID and the undefined memory are not as good quality as good randomness. So, even without Debian’s intervention, it was a bad idea. The undefined memory triggered valgrind, and after Debian’s patch, if it weren’t because of the PID, all keys would have been reduced to 0 randomness, which would have probably raised the alarm much sooner.

{kind=link}
no more patching fuzzers to allow that one program to compile. Fix the program
Agreed.
Remember Debian’s OpenSSL fiasco? The one that affected all the other derivatives as well, including Ubuntu.
It all started because OpenSSL did add to the entropy pool a bunch uninitialized memory and the PID. Who the hell relies on uninitialized memory ever? The Debian maintainer wanted to fix Valgrind errors, and submitted a patch. It wasn’t properly reviewed, nor accepted in OpenSSL. The maintainer added it to the Debian package patch, and then everything after that is history.
Everyone blamed Debian “because it only happened there”, and definitely mistakes were done on that side, but I surely blame much more the OpenSSL developers.
Is it, really? If the whole point of the library is dealing with binary files, how are you even going to have automated tests of the library?
The scary thing is that there is people still using autotools, or any other hyper-complicated build system in which this is easy to hide because who the hell cares about learning about Makefiles, autoconf, automake, M4 and shell scripting at once to compile a few C files. I think hiding this in any other build system would have been definitely harder. Check this mess:
dnl Define somedir_c_make. [$1]_c_make=`printf '%s\n' "$[$1]_c" | sed -e "$gl_sed_escape_for_make_1" -e "$gl_sed_escape_for_make_2" | tr -d "$gl_tr_cr"` dnl Use the substituted somedir variable, when possible, so that the user dnl may adjust somedir a posteriori when there are no special characters. if test "$[$1]_c_make" = '\"'"${gl_final_[$1]}"'\"'; then [$1]_c_make='\"$([$1])\"' fi if test "x$gl_am_configmake" != "x"; then gl_[$1]_config='sed \"r\n\" $gl_am_configmake | eval $gl_path_map | $gl_[$1]_prefix -d 2>/dev/null' else gl_[$1]_config='' fi
I’m not fully sure what the intent of the joke is, but note that yes, it’s true that a header typically just has the prototype. However, tons of more advanced libraries are “header-only”. Everything is in a single header originally, in development, or it’s a collection of headers (that optionally gets “amalgamated” as a single header). This is sometimes done intentionally to simplify integration of the library (“just copy this files to your repo, or add it as a submodule”), but sometimes it’s entirely necessary because the code is just template code that needs to be in a header.
C++ 20 adds modules, and the situation is a bit more involved, but I’m not confident enough of elaborating on this. :) Compile times are much better, but it’s something that the build system and the compilers needs to support.
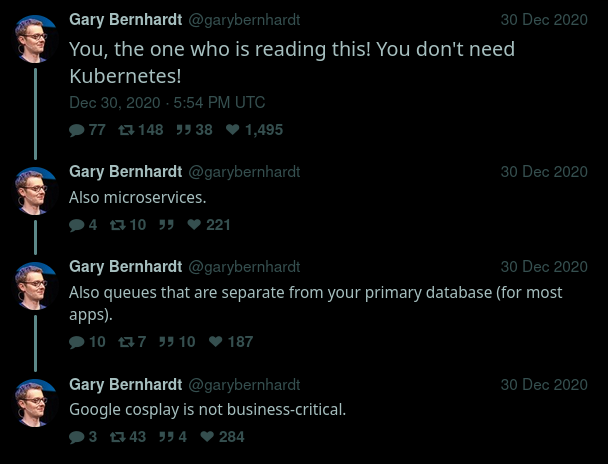
Precisely, Gary Bernhardt has given a talk on ideology. I don’t think he’s precisely someone who thinks in absolutes. It’s just preaching that some stuff is (probably) used more than it should. I’ve seen way, way, way worse projects that over engineered things and made things slow and unmanageable, than the opposite. Of course, everyone has seen different things, and our perceptions are amplified and biased by that.
{kind=link}
The github project page is for developers, and Github already gives you tons of ways to make a user website. Don’t ask your users to visit github.com/group/project, make them visit group.github.io/project, like any sane person.
Same with Gitlab, BTW.
And if you don’t like the full static site, use the wiki, or guide your users in the first paragraphs of the README so they find the user information if they must.
Sorry, could you clarify what you mean? I don’t see the difference. Isn’t the author complaining about Canonical for the policy enforcement?
Thanks. I should have linked to that myself, perhaps.
{kind=link}
Sometimes that’s part of the issue (or the whole deal), but sometimes it’s not even that.
Sometimes it’s that someone asked something difficult and elaborate to answer, which has been answered a ton of times, and it’s tedious to answer again and again. But if someone answers with misinformation or even straight FUD, then one needs to feel the urge to correct that to prevent misinformation.
I suffered that with questions in r/QtFramework. Tons of licensing questions, repeated over and over, from people who have not bothered to read a bit about such a well known and popular license as LGPL. Then someone who cares little for the nuance answers something heavy handed, and paints a wrong picture. Then I can’t let the question pass. I need to correct the shitty answer. :-(
You entirely ignored this part.
You basically proved my point in doing so, BTW. You cannot do what you claimed with an LLM. And I’m not saying, and I never said before “ChatGPT” or “OpenAI”. I don’t understand why you think that I might be “defending these hypocritical companies”, when I literally said the opposite at the end.
You are entirely fooled by the output of ChatGPT and you are not arguing in good faith (or you are entirely unable to understand what I said).