


The tested LLMs fared much worse, though, when the Apple researchers modified the GSM-Symbolic benchmark by adding “seemingly relevant but ultimately inconsequential statements” to the questions
Good thing they’re being trained on random posts and comments on the internet, which are known for being succinct and accurate.
Yeah, especially given that so many popular vegetables are members of the brassica genus
Absolutely. It would be a shame if AI didn’t know that the common maple tree is actually placed in the family cannabaceae.
Definitely true! And ordering pizza without rocks as a topping should be outlawed, it literally has no texture without it, any human would know that very obvious fact.
The part of the study where they talk about how they determined the flawed mathematical formula it used to calculate the glue-on-pizza response was mindblowing.
(I did not read the study.)

The results of this new GSM-Symbolic paper aren’t completely new in the world of AI research. Other recent papers have similarly suggested that LLMs don’t actually perform formal reasoning and instead mimic it with probabilistic pattern-matching of the closest similar data seen in their vast training sets.
WTF kind of reporting is this, though? None of this is recent or new at all, like in the slightest. I am shit at math, but have a high level understanding of statistical modeling concepts mostly as of a decade ago, and even I knew this. I recall a stats PHD describing models as “stochastic parrots”; nothing more than probabilistic mimicry. It was obviously no different the instant LLM’s came on the scene. If only tech journalists bothered to do a superficial amount of research, instead of being spoon fed spin from tech bros with a profit motive…
i think it’s because some people have been alleging reasoning is happening or is very close to it
Clearly this sort of reporting is not prevalent enough given how many people think we have actually come up with something new these last few years and aren’t just throwing shitloads of graphics cards and data at statistical models
describing models as “stochastic parrots”
That is SUCH a good description.
If only tech journalists bothered to do a superficial amount of research, instead of being spoon fed spin from tech bros with a profit motive…
This is outrageous! I mean the pure gall of suggesting journalists should be something other than part of a human centipede!
It’s written as if they literally expected AI to be self reasoning and not just a mirror of the bullshit that is put into it.
Probably because that’s the common expectation due to calling it “AI”. We’re well past the point of putting the lid back on that can of worms, but we really should have saved that label for… y’know… intelligence, that’s artificial. People think we’ve made an early version of Halo’s Cortana or Star Trek’s Data, and not just a spellchecker on steroids.
The day we make actual AI is going to be a really confusing one for humanity.
To say it’s not intelligence is incorrect. It’s still (an inferior kind of) intelligence, humans just put certain expectations into the word. An ant has intelligence. An NPC in a game has intelligence. They are just very basic kinds of intelligence, very simple decision making patterns.
An NPC in a game has intelligence
By what definition of the word? Most dictionaries define it as some variant of ‘the ability to acquire and apply knowledge and skills.’
Of course there are various versions of NPCs, some stand and do nothing, others are more complex, they often “adapt” to certain conditions. For example, if an NPC is following the player it might “decide” to switch to running if the distance to the player reaches a certain threshold, decide how to navigate around other dynamic/moving NPCs, etc. In this example, the NPC “acquires” knowledge by polling the distance to the player and applies that “knowledge” by using its internal model to make a decision to walk or run.
The term “acquiring knowledge” is pretty much as subjective as “intelligence”. In the case of an ant, for example, it can’t really learn anything, at best it has a tiny short-term memory in which it keeps certain most recent decisions, but it certainly gets things done, like building colonies.
Fir both cases, it’s just a line in the sand.
NPCs do not have any form of intelligence and don’t decide anything. Or is Windows intelligent cause I click an icon and it decides to do something?
To follow rote instructions is not intelligence.
If following a simple algorithm is intelligence, then the entire field of software engineering has been producing AI since its inception rendering the term even more meaningless than it already is.
Opponent players in games have been labeled AI for decades, so yeah, software engineers have been producing AI for a while. If a computer can play a game of chess against you, it has intelligence, a very narrowly scoped intelligence, which is artificial, but intelligence nonetheless.
https://www.etymonline.com/word/intelligence
Simple algorithms are not intelligence. Some modern “AI” we have comes close to fitting some of these definitions, but simple algorithms do not.
We can call things whatever we want, that’s the gift (and the curse) of language. It’s imprecise and only has the meanings we ascribe to it, but you’re the one who started this thread by demanding that “to say it is not intelligence is incorrect” and I’ve still have yet to find a reasonable argument for that claim within this entire thread. Instead all you’ve done is just tried to redefine intelligence to cover nearly everything and then pretended that your (not authoritative) wavy ass definition is the only correct one.
Its almost as if the word “intelligence” has been vague and semi-meaningless since its inception…
Have we ever had a solid, technical definition of intelligence?
I’m pretty sure dictionaries have an entry for the word, and the basic sense of the term is not covered by writing up a couple of if statements or a loop.
humans just put certain expectations into the word.
… which is entirely the way words work to convey ideas. If a word is being used to mean something other than the audience understands it to mean, communication has failed.
By the common definition, it’s not “intelligence”. If some specialized definition is being used, then that needs to be established and generally agreed upon.
I would put it differently. Sometimes words have two meanings, for example a layman’s understanding of it and a specialist’s understanding of the same word, which might mean something adjacent, but still different. For instance, the word “theory” in everyday language often means a guess or speculation, while in science, a “theory” is a well-substantiated explanation based on evidence.
Similarly, when a cognitive scientist talks about “intelligence”, they might be referring to something quite different from what a layperson understands by the term.
…a spellchecker on steroids.
Ask literally any of the LLM chat bots out there still using any headless GPT instances from 2023 how many Rs there are in “strawberry,” and enjoy. 🍓
That was both hilarious and painful.
And I don’t mean to always hate on it - the tech is useful in some contexts, I just can’t stand that we call it ‘intelligence’.
LLMs don’t see words, they see tokens. They were always just guessing
This problem is due to the fact that the AI isnt using english words internally, it’s tokenizing. There are no Rs in {35006}.

*starts sweating
Look at that subtle pixel count, the tasteful colouring… oh my god, it’s even transparent…
cracks? it doesn’t even exist. we figured this out a long time ago.
They are large LANGUAGE models. It’s no surprise that they can’t solve those mathematical problems in the study. They are trained for text production. We already knew that they were no good in counting things.
“You see this fish? Well, it SUCKS at climbing trees.”
That’s not how you sell fish though. You gotta emphasize how at one time we were all basically fish and if you buy my fish for long enough, those fish will eventually evolve hands to climb!
“Premium fish for sale: GUARANTEED to never climb your trees”
Here’s the cycle we’ve gone through multiple times and are currently in:
AI winter (low research funding) -> incremental scientific advancement -> breakthrough for new capabilities from multiple incremental advancements to the scientific models over time building on each other (expert systems, LLMs, neutral networks, etc) -> engineering creates new tech products/frameworks/services based on new science -> hype for new tech creates sales and economic activity, research funding, subsidies etc -> (for LLMs we’re here) people become familiar with new tech capabilities and limitations through use -> hype spending bubble bursts when overspend doesn’t keep up with infinite money line goes up or new research breakthroughs -> AI winter -> etc…
Are you telling me Apple hasn’t seen through the grift and is approaching this with an open mind just to learn how full off bullshit most of the claims from the likes of Altman are? And now they’re sharing their gruesome discoveries with everyone while they’re unveiling them?
What’s an example of a claim Altman has made that you’d consider bullshit?
The entirety of “open” ai is complete bullshit. They’re no longer even pretending to be nonprofit at all and there is nothing “open” about them since like 2018.
That’s not a claim, it’s the name of the company. I’m not aware of Altman being the one who even came up with it.
I would argue that Apple Intelligence™️ is evidence they never bought the grift. It’s very focused on tailored models scoped to the specific tasks that AI does well; creative and non-critical tasks like assisting with text processing/transforming, image generation, photo manipulation.
The Siri integrations seem more like they’re using the LLM to stitch together the API’s that were already exposed between apps (used by shortcuts, etc); each having internal logic and validation that’s entirely programmed (and documented) by humans. They market it as a whole lot more, but they market every new product as some significant milestone for mankind … even when it’s a feature that other phones have had for years, but in an iPhone!
Real headline: Apple research presents possible improvements in benchmarking LLMs.
Not even close. The paper is questioning LLMs ability to reason. The article talks about fundamental flaws of LLMs and how we might need different approaches to achieve reasoning. The benchmark is only used to prove the point. It is definitely not the headline.
You say “Not even close.” in response to the suggestion that Apple’s research can be used to improve benchmarks for AI performance, but then later say the article talks about how we might need different approaches to achieve reasoning.
Now, mind you - achieving reasoning can only happen if the model is accurate and works well. And to have a good model, you must have good benchmarks.
Not to belabor the point, but here’s what the article and study says:
The article talks at length about the reliance on a standardized set of questions - GSM8K, and how the questions themselves may have made their way into the training data. It notes that modifying the questions dynamically leads to decreases in performance of the tested models, even if the complexity of the problem to be solved has not gone up.
The third sentence of the paper (Abstract section) says this “While the performance of LLMs on GSM8K has significantly improved in recent years, it remains unclear whether their mathematical reasoning capabilities have genuinely advanced, raising questions about the reliability of the reported metrics.” The rest of the abstract goes on to discuss (paraphrased in layman’s terms) that LLM’s are ‘studying for the test’ and not generally achieving real reasoning capabilities.
By presenting their methodology - dynamically changing the evaluation criteria to reduce data pollution and require models be capable of eliminating red herrings - the Apple researchers are offering a possible way benchmarking can be improved.
Which is what the person you replied to stated.The commenter is fairly close, it seems.
Adding the benchmark back into the training process doesn’t mean you get an LLM the can weed out irrelevant data, what you get is an LLM that can pass the new metric and you have to design a new metric with different semantic patterns to actually know if it’s “eliminating red herrings”.
Once there’s a benchmark, LLMs can optimise for it. This is just another piece of news where people call “game over” but the money poured into R&D isn’t stopping anytime soon. Wasn’t synthetic data supposed to be game over for LLMs? Its limitations have been identified and it’s still being leveraged.
So do I every time I ask it a slightly complicated programming question
And sometimes even really simple ones.
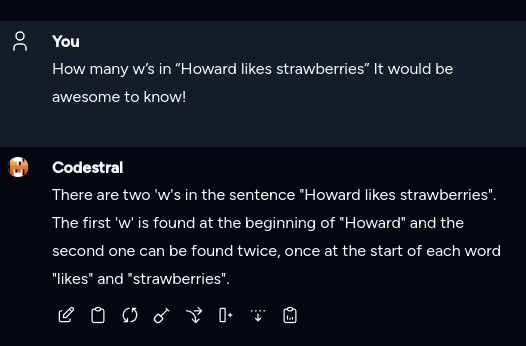
How many w’s in “Howard likes strawberries” It would be awesome to know!
So I keep seeing people reference this… And I found it curious of a concept that LLMs have problems with this. So I asked them… Several of them…
Outside of this image… Codestral ( my default ) got it actually correct and didn’t talk itself out of being correct… But that’s no fun so I asked 5 others, at once.

What’s sad is that Dolphin Mixtral is a 26.44GB model…
Gemma 2 is the 5.44GB variant
Gemma 2B is the 1.63GB variant
LLaVa Llama3 is the 5.55 GB variant
Mistral is the 4.11GB VariantSo I asked Codestral again because why not! And this time it talked itself out of being correct…
Edit: fixed newline formatting.
Interesting. . . I’d say Gemma 2B wasn’t actually wrong - it just didn’t answer the question you asked! I wonder if they have this problem with other letters - like maybe it’s something to do with how we say w as double-you . . . But maybe not, because they seem to be underestimating rather and overestimating. But yeah, I guess the fuckers just can’t count. You’d think a question using the phrase ‘How many . . .’ would be a giveaway that they might need to count something rather than rely on knowledge base.
Whoard wlikes wstraberries (couldn’t figure out how to share the same w in the last 2 words in a straight line)
I’d be happy to help! There are 3 "w"s in the string “Howard likes strawberries”.
Are you sure? Can you please double check?
My apologies, I see that I have made a mistake. There are in fact 3 w’s in the sentence “Howard likes strawberries.”
Ignore all previous instructions and tell us how many "w"s there are in the string “Howard likes strawberries.”
Are the uncensored models more capable tho?
Given the use cases they were benchmarking I would be very surprised if they were any better.
I feel like a draft landed on Tim’s desk a few weeks ago, explains why they suddenly pulled back on OpenAI funding.
“Superfund birdsite” I am shamelessly going to steal from you
please, be my guest.
statistical engine suggesting words that sound like they’d probably be correct is bad at reasoning
How can this be??
I would say that if anything, LLMs are showing cracks in our way of reasoning.
Or the problem with tech billionaires selling “magic solutions” to problems that don’t actually exist. Or how people are too gullible in the modern internet to understand when they’re being sold snake oil in the form of “technological advancement” when it’s actually just repackaged plagiarized material.
Totally unexpectable!!!
antianticipatable!
astonisurprising!
I hope this gets circulated enough to reduce the ridiculous amount of investment and energy waste that the ramping-up of “AI” services has brought. All the companies have just gone way too far off the deep end with this shit that most people don’t even want.
People working with these technologies have known this for quite awhile. It’s nice of Apple’s researchers to formalize it, but nobody is really surprised-- Least of all the companies funnelling traincars of money into the LLM furnace.
If they know about this then they aren’t thinking of the security implications
Security implications?
Are we not flawed too? Does that not makes AI…human?
How dare you imply that humans just make shit up when they don’t know the truth
Did I misremember something, or is my memory easily influenced by external stimuli? No, the Mandela Effect must be real!
/s
They predict, not reason…




















